May 21, 2019
3
min read
Using Markerless Augmented Reality for Digital Avatars
How do we get digital objects to play well with reality (and with the human at the center of an augmented experience)?
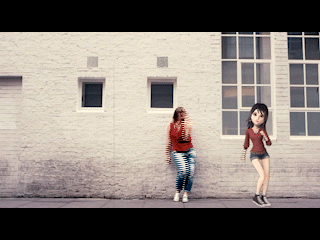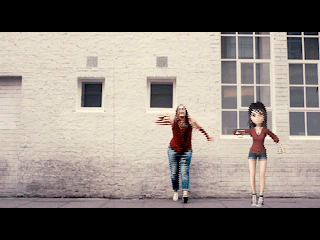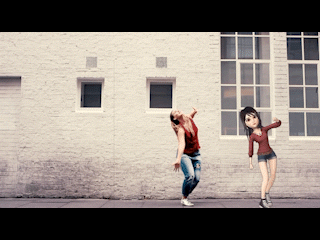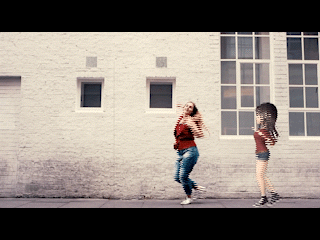
How do we get digital objects to play well with reality (and with the human at the center of an augmented experience)?
How do we get digital objects to play well with reality (and with the human at the center of an augmented experience)? Creating compelling AR experiences hangs in the balance of this question and the way we integrate virtual overlays with real world environments. Pokemon Go, the breakout AR success of 2016, leveraged location-based mobile AR to solve this problem, proving that AR could inspire a newfound engagement with the world given the right digital easter eggs, distributed just so. Other promising advancements in augmented reality have followed from markerless augmented reality, or the ability to map digital objects to an environment without prior information about—or physical markers and trackers within—that environment.

Techniques in the field of computer vision have enabled better surface detection and orientation, as well as depth perception for spawning digital objects with more accuracy. AR e-commerce and design experiences rely on this improved accuracy to render digital objects at scale and prototype placement. Another exciting application of computer vision in augmented reality is in the field of pose estimation—without which human expression through markerless augmented reality would be limited.

2D pose estimation, which extracts human joint information across a flat plane (along the x and y axes), can be used for applications needing behavior recognition, gesture recognition, and abstracted human input into an environment. However, in order to fully capture the motion of a user, implementing 3D pose estimation is required. 3D pose estimation reconstructs human joint information across three axes (the x,y,z axes), capturing more true-to-life motion data in 3D. The key challenge in 3D pose estimation for AR is generating joint depth from a 2D video feed; motions with limb occlusion and non-lateral movements can be barriers to creating natural, fluid 3D motions.
At DeepMotion, developing a robust AR digital avatar solution was a clear way to bring the exciting applications of 3D pose estimation to more users through mobile devices. Full body capture and reconstruction enables more expressive forms of social AR, granting end-users the ability to communicate through body language and personalized digital avatar animation. For content creators—who experience severe cost and time constraints around generating character animation data—a point-and-shoot markerless motion capture pipeline could be a transformative addition to creative toolsets.
We found that developing the most reliable 3D pose estimation solution meant pairing our vision model with character physics. At the launch of our markerless AR avatar solution we explained why; “the DeepMotion solution derives additional accuracy from the physics-based character model...adding necessary body constraints that help translate quick or complicated motions from 2D to 3D.” With a fully simulated character, the results are confined to the physically feasible. This helps generate lifelike results and correct errors from occlusion and non-lateral motions. With a physics-enabled character, we are also able to add other physics-enabled objects into an environment for exciting AR interactions. In the video below, a boxing motion can be used to punch a virtual punching bag in real-time, giving the user a richer digital experience.
Beyond real-time user tracking, to digital avatar creation, and cheaper motion capture solutions for animation, we anticipate being able to use markerless augmented reality character data for motion training. With a shared foundation in character physics, our digital avatar solution is poised to open new doors for AI character simulation and the world of Motion Intelligence.

.jpg)
.jpg)
